During the past few decades, I have been involved in multiple embedded IT systems in distinct roles. I have been developing, maintaining, and designing. I have worked with individual subcomponents and with complete systems. I have seen ready-made stuff, implemented some myself and see others create new in parallel.
Many times, the result has been somewhat working. Many times, however, sub-optimality has been involved in some way. Part of the blame falls on me and part on other people. I am in no position to hold anyone else responsible for the problematic stuff than myself. And to be honest it has been many times a great learning experience to work out all the kinks out there and challenge previous thinking about the state of things.
IT System Design 101 will be a series of articles I will be writing about how to design an IT system. Emphasis will be on systems with embedded actors. There is no guarantee that the design patterns I’m going to lay down will result in a perfect system. I am quite sure though that the result will not be the worst possible.
Below will be an updating table of contents about already written and upcoming articles.
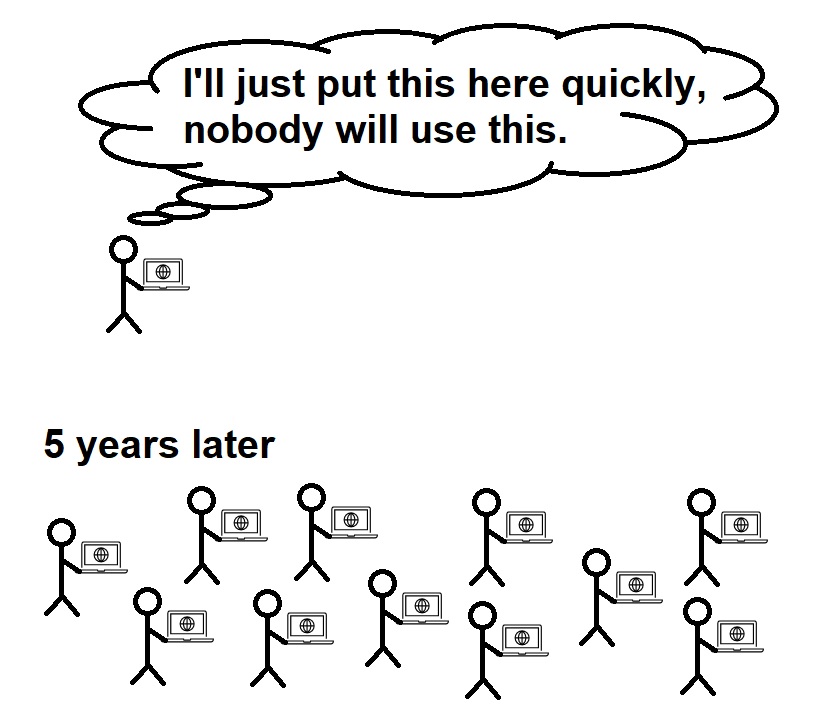
IT System Design 101: Nothing is as prevalent as temporary mock or debug program
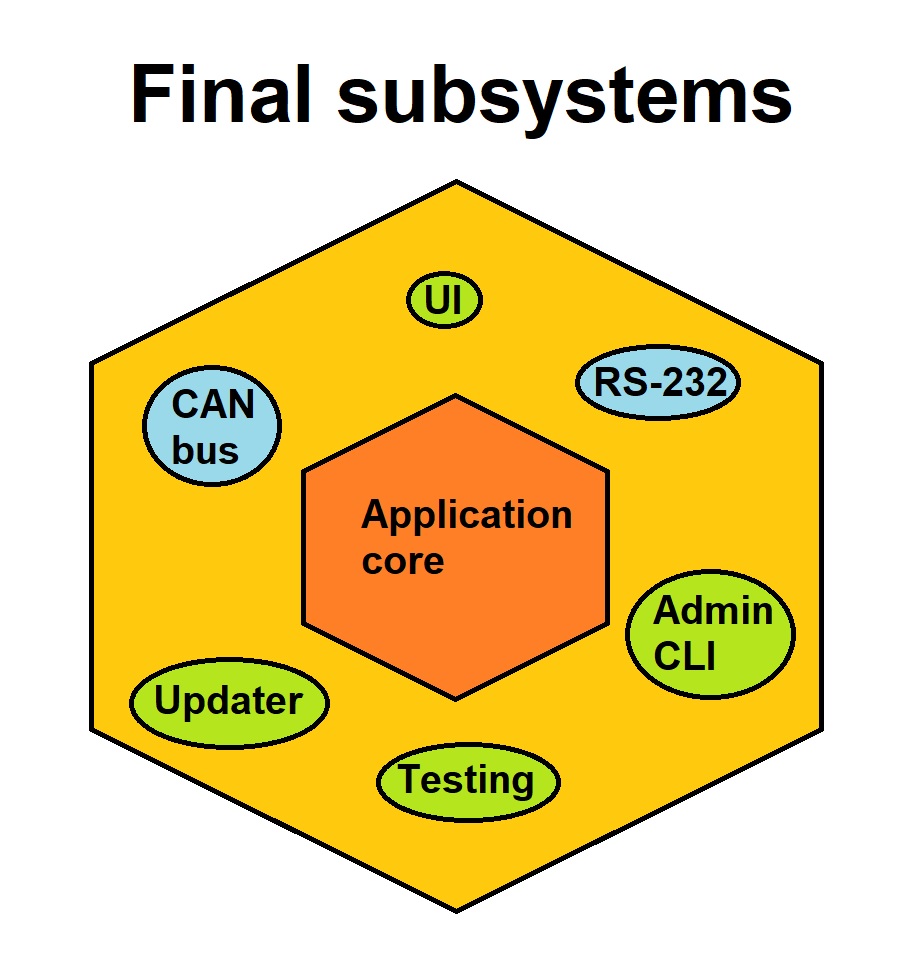
IT System Design 101: Subsystems are NOT just dumb pipes
IT System Design 101: Design for Deltas
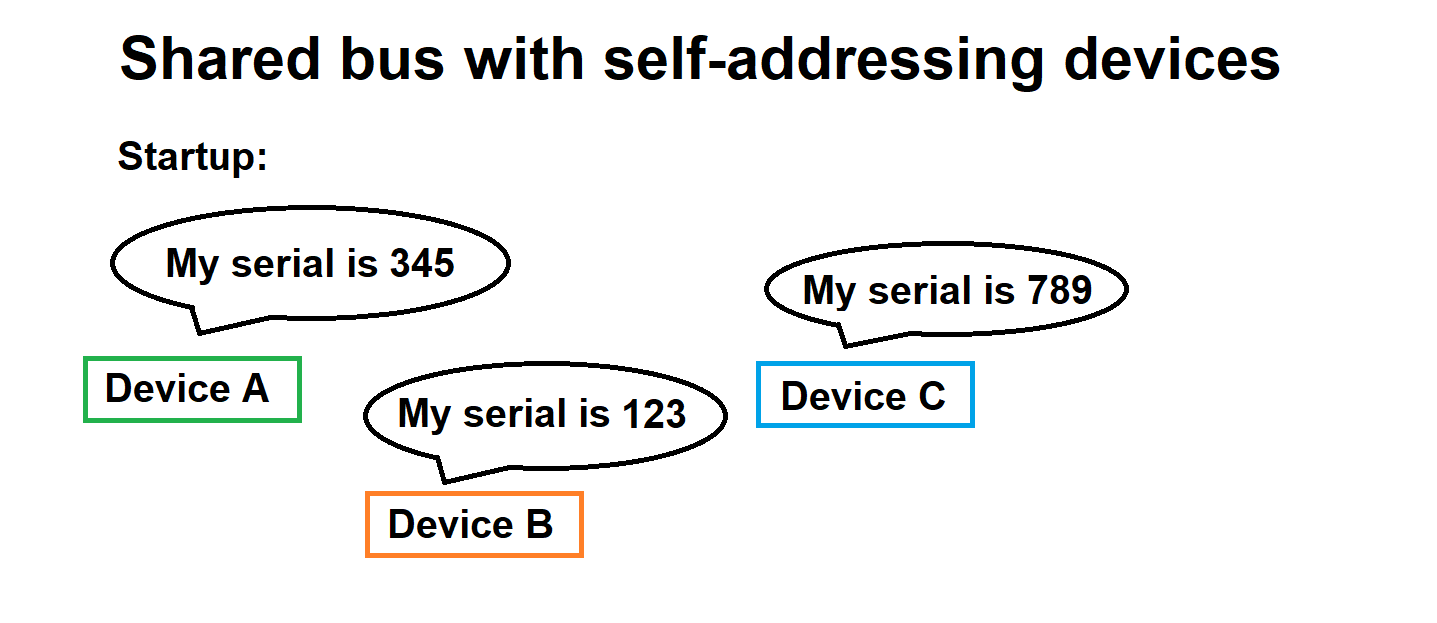
IT System Design 101: Decoupling of address and entity data in a self-addressing bus