One design pattern in non-trivial IT systems is as follows. There exists a central authority of data and business logic with subsystems interfacing it. This, contemporarily somewhat obvious model, is called the Hexagonal Architecture and was first formalized in writing by Alistair Cockburn in 2005 (see https://en.wikipedia.org/wiki/Hexagonal_architecture_(software) ).
What is a subsystem in our context then? It is a system managing a domain (“a collection of things”), communicating to the central authority with a well-defined API. As with everything else, subsystems can be defined and implemented in different ways. One bad way to implement subsystem is to treat it as just a dumb pipe just passing data around. I will explain my rationale.
Philosophically, how should we decide what goes into a subsystem? There are multiple possible methods to look into this. One idea is to write a subsystem for different types of data link type. For example, one to handle CAN bus, one to handle RS-232, one to handle Bluetooth and so on. Another possibility is to create subsystems from individual use-case properties. For example, user interface could be one and admin command line could be another. Usually, we end up mixing a bit from each system. See illustration below.

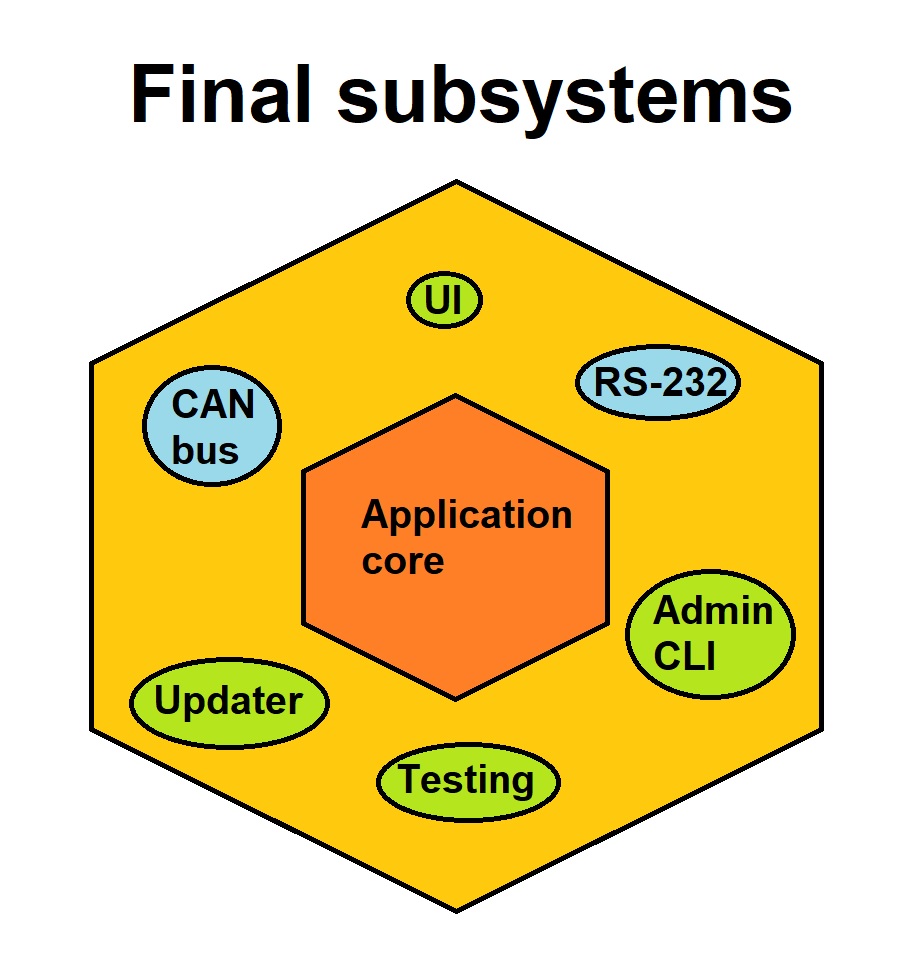
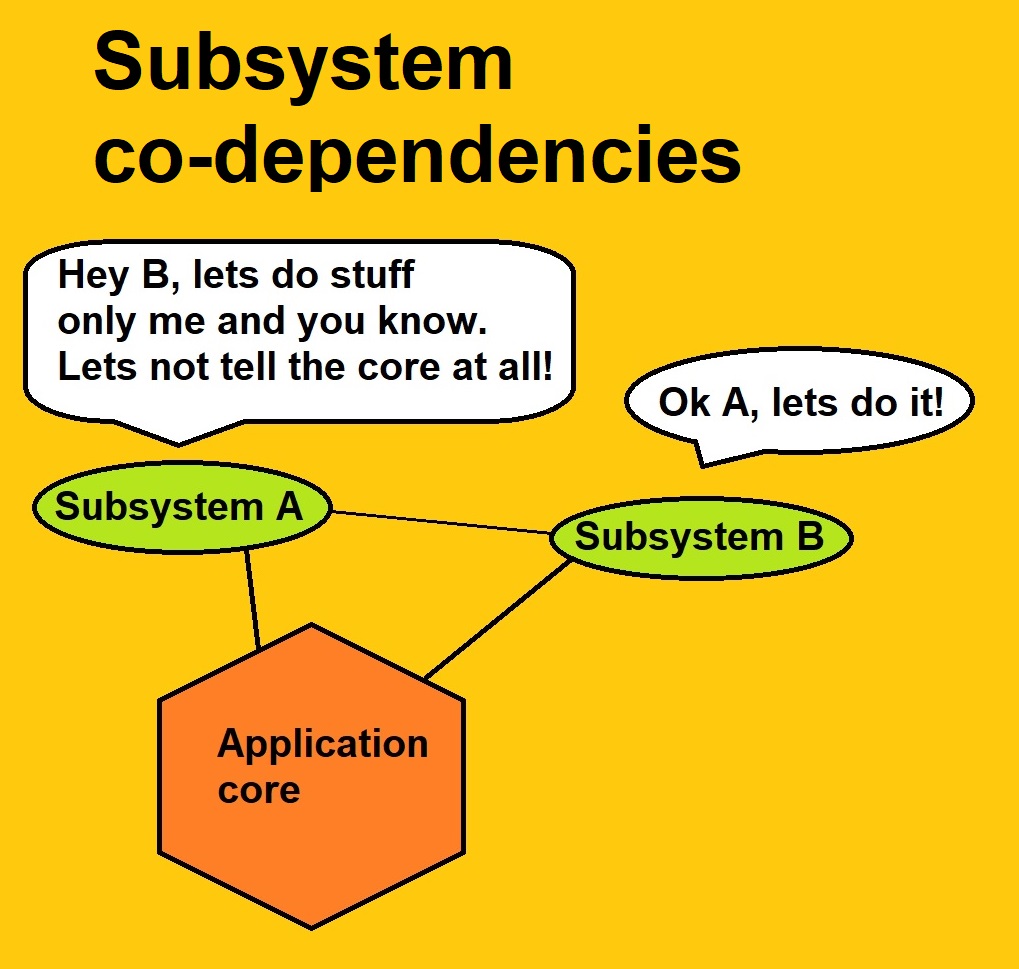
A couple of things can go wrong in subsystem definition and partitioning. One thing is scope problems. Scope can be too large, creating subsystems which are big behemoths. Another end of this spectrum is putting every possible tiny functionality into a dedicated subsystem, creating over-microserviceation. This in turn is bad, because every subsystem/service has a cost, and that cost gets added up. There needs to be a balance. Another common problem is subsystem co-dependability. It means that even as the individual subsystems are intended to be somewhat independent of each other (for better maintenance and general development), there still exist interactions bypassing the central authority or application core. This is not good practice. Another illustration below shows what I mean.
Another issue worth mentioning about subsystem problems is not related to partitioning per se, but about generic interfacing. It might be that the API the subsystems use to communicate to application core is error-prone or otherwise underdeveloped and not well-thought out in general.
Next it is time to address the verbatim problem stated in the topic. I wrote “Subsystems are NOT just dumb pipes”. What does this mean and why do I think it means it? There is a possibility to write subsystems in a way where the component makes only minimal intervention or calculation about the data it receives externally. Basically, in this way the subsystem acts as a dumb pipe, just mindlessly passing external data to the application core.
This is a problematic choice of design for multiple reasons. First, the subsystem is an expert of its own domain. By passing all data blindly, it outsources all the interpretation responsibilities to the application core. This means the core needs to in practice know also about the inner workings of the subsystem component. This is unnecessary coupling as both components should be somewhat independent (and communicating via a well-established API).
Also, in some situations, the “dumb pipes” approach creates insane amounts of redundant messages passing from subsystem to application core. And finally, relating to this, if the calculations regarding data utilized in the application core require more resources than the same stuff done in the subsystem, we are obviously losing resources.
As a very pathological example, think if application core is written for some strange reason with let’s say JavaScript. And say the subsystem is written with C. Also, let’s assume we need to make some bit operations every time for incoming data. Now, every time we just pass the data to the slower JavaScript without touching it in C, we are losing efficiency. This is especially true with embedded systems, where resources are scarce. Thinking such system being like a PC with virtually unlimited resources is very harmful. With constrained domains there is no premature optimization. Speaking of which I briefly present the final problem in the “dumb pipes” approach. In some situations, we also lose the ability to make cache-based sub-optimizations.
There is one extremely helpful byproduct of creating correctly partitioned subsystems with well-defined APIs, but we will discuss it more in another article called IT System Design 101: Design for Deltas.